云服务器 ECS
- 新功能发布记录
- 产品简介
- 产品定价
- 个人版快速入门
- 企业版快速入门
- 实例
- 镜像
- 块存储
- 快照
- 网络
- 安全
- 标签与资源
- 部署与运维
- 迁移服务
- 最佳实践
-
建站教程
- 建站零基础入门
- 自助建站方式汇总
- 搭建WordPress网站
- 创建基于ECS和RDS的WordPress环境
- 部署LNMP
- 部署Java Web
- 部署Node.js项目(CentOS)
- 搭建Magento电子商务网站(CentOS 7)
- 镜像部署 Windows 环境
- 部署Web环境(Windows)
- 快速搭建 ThinkPHP 框架
- 快速搭建 phpwind 论坛系统
- GitLab的安装及使用
- 快速使用AMH建站
- ECS搭建Microsoft SharePoint 2016
- ECS上搭建Docker(CentOS7)
- 部署LAMP
- 在ECS上部署数据库
- 阿里云安装SharePoint 2016
- 部署Linux主机管理系统WDCP
- PostgreSQL 本地Slave搭建步骤
- 搭建Joomla基础管理平台
- 部署Ghost博客(CentOS 7)
- Drupal建站教程(CentOS7)
- 部署RabbitMQ
- 搭建和使用SVN
- 快速搭建 Moodle 课程管理系统
- 搭建FTP站点
- Vim教程
- 使用MySQL数据库
-
API参考
- 简介
- API 概览
- ECS API快速入门
- HTTP调用方式
- 鉴权规则
-
实例
- RunInstances
- CreateInstance
- StartInstance
- StopInstance
- RebootInstance
- DeleteInstance
- AttachInstanceRamRole
- DetachInstanceRamRole
- DescribeInstanceStatus
- DescribeInstances
- DescribeInstanceVncUrl
- DescribeUserData
- DescribeInstanceAutoRenewAttribute
- DescribeInstanceRamRole
- DescribeSpotPriceHistory
- DescribeInstanceTypeFamilies
- DescribeInstanceTypes
- ModifyInstanceVpcAttribute
- ModifyInstanceAttribute
- ModifyInstanceVncPasswd
- ModifyInstanceAutoReleaseTime
- ModifyInstanceAutoRenewAttribute
- ModifyInstanceChargeType
- ModifyInstanceSpec
- ModifyPrepayInstanceSpec
- RenewInstance
- ReactivateInstances
- 启动模板
- 磁盘
- 预留实例券
- 镜像
- 快照
-
安全组
- CreateSecurityGroup
- AuthorizeSecurityGroup
- AuthorizeSecurityGroupEgress
- RevokeSecurityGroup
- RevokeSecurityGroupEgress
- JoinSecurityGroup
- LeaveSecurityGroup
- DeleteSecurityGroup
- DescribeSecurityGroupAttribute
- DescribeSecurityGroups
- DescribeSecurityGroupReferences
- ModifySecurityGroupAttribute
- ModifySecurityGroupPolicy
- ModifySecurityGroupRule
- ModifySecurityGroupEgressRule
- 部署集
- SSH 密钥对
- 网络
- 弹性网卡
- 系统事件
- 运维与监控
- 云助手
- 高性能集群
- 标签
- 地域
- 其他接口
- 附录
-
数据类型
- AccessPointSetType
- AccessPointType
- AccountType
- AutoSnapshotPolicyType
- AutoSnapshotExecutionStatusType
- AvailableDiskCategoriesType
- AvailableInstanceTypesType
- AvailableResourceCreationType
- AvailableResourcesType
- BandwidthPackageItemType
- BandwidthPackageSetType
- DiskDeviceMapping
- DiskItemType
- DiskMonitorDataType
- DiskSetType
- EipAddressAssociateType
- ImageType
- InstanceAttributesType
- InstanceMonitorDataType
- InstanceRamRoleSetType
- InstanceStatusItemType
- InstanceStatusSetType
- InstanceTypeFamilyItemType
- InstanceTypeItemType
- IpAddressSetType
- IpRangeSetType
- KeyPairItemType
- KeyPairSetType
- OperationLocksType
- OperationProgressType
- PermissionSetType
- PermissionType
- PublicIpAddressItemType
- PublicIpAddressSetType
- RegionType
- RelatedItemType
- ResourceTypeCountItem
- SecurityGroupIdSetType
- SecurityGroupItemType
- SecurityGroupSetType
- ShareGroupType
- SnapshotLinkType
- SnapshotType
- TagSetItem
- TaskType
- VpcAttributesType
- ZoneType
- AssociatedPublicIp
- Link
- NetworkInterfaceSet
- NetworkInterfaceType
- PriceInfoType
- PriceType
- PrivateIpSet
- ReferencingSecurityGroup
- RulesType
- SecurityGroupReference
- SpotPriceType
- SDK参考
-
常见问题
-
故障处理
- 无法远程连接 ECS 实例排查流程图
- 无法连接Windows实例
- 无法连接Linux实例
- 无法访问 ECS 实例上运行的网站
- Windows实例带宽和CPU跑满或跑高排查
- Linux实例带宽和CPU跑满或跑高排查
- Windows实例网络访问丢包延时高
- Linux实例网站访问丢包延时高
- 监控CPU和内存的日志工具
- ping 丢包或不通时链路测试说明
- 网络异常时抓包操作说明
- 如何在 Windows Server 安装 IIS 服务时指定备用源路径
- 排查 Linux 实例异常 CPU 使用率 100%
- 快速排查无法打开 ECS 实例上运行的网站
- CentOS7实例随机性夯机问题
- ECS资源监控中网络流量显示无数据
- Tomcat服务启动非常缓慢
- 常见问题汇总
-
功能相关
-
实例
- GPU实例FAQ
- 弹性裸金属服务器FAQ
- 超级计算集群(SCC)FAQ
- ECS Linux服务器到期续费后站点无法访问处理
- ECS 实例长时间为 Starting 状态,且 AliyunService 被禁用或被删除
- ECS实例管理FAQ
- 企业级实例 FAQ
- 升级 ECS 实例规格和配置 FAQ
- i1实例规格族FAQ
- 实例规格族 d1 和 d1ne FAQ
- 抢占式实例FAQ
- ECS服务器如何让OSS支持HTTPS
- 操作f1实例
- ECS实例转移和更换公网IP地址的说明
- 云服务器 ECS 创建多少个网站
- Linux 系统云服务器 ECS 使用导航
- Mac OS 如何通过 FTP 工具上传文件
- 如何查看网站首页大小
- 无法在 ECS 实例上登录淘宝网
- 云服务器 ECS 购买须知
- 所选的地域没有需要的资源
- 英特尔 SGX 基础介绍
- ECS实例无法加载内核启动
- 安全组
-
网络
- ECS 实例网络带宽 FAQ
- 包月ECS带宽按流量计费FAQ
- 云盾是否有屏蔽 IP 的功能
- 能 ping 通但端口不通时端口可用性探测说明
- 如何通过防火墙策略限制对外扫描行为
- 客户端本地到ECS服务器丢包的检查方法
- 查看云服务器 ECS 公网流量统计总和
- 检测本地网络到ECS实例之间的网络状况
- Ubuntu系统ECS使用“如何通过防火墙策略限制对外扫描行为”脚本之后出现无法远程、数据库连接不上
- 手机移动端网络路由跟踪探测方式
- ECS云服务器如何禁用公网IP
- ECS Ubuntu系统单独禁用和启动内外网卡命令
- ECS 实例子网划分和掩码表示方法
- IP地址查询定位
- 禁止网卡
- 服务器黑洞
- 弹性公网IP查看流量和带宽监控信息
- 如何处理 ECS 实例对外 DDoS 攻击导致被锁定
- 什么是云服务器 ECS 的入网带宽和出网带宽
- 访问ECS服务器的网站提示“由于你访问的URL可能对网站造成安全威胁,您的访问被阻断”
- 云监控中的ECS带宽和ECS控制台中看到的带宽不一致
- ECS 实例停止(关机)后按量付费带宽仍产生流量
- BGP机房介绍
- Ping ECS实例的IP地址间歇性丢包
- 云服务器ECS网络故障诊断
- API
-
其他
- ECS Docker实践文档
- 云服务器 ECS 怎么取消流量清洗
- 克隆ECS服务器的方法
- 弹性伸缩报警任务提示数据不足
- ECS反向解析的申请流程
- 数据传输服务DTS实时同步功能是只同步表结构的方法
- 如何获取控制台RequestId
- ECS中网站被恶意域名解析模仿站点处理
- ECS服务器用IE浏览器访问下载提示smartscreen筛选器联机服务暂不可用
- ECS 默认没有启用虚拟内存或SWAP说明
- 中国大陆用户购买其他国家和地区实例资源 FAQ
- ECS Linux 实例设置 Locale 变量
- 产品计费FAQs
- Cron 表达式取值说明
- 修改Tomcat 7日志的记录时间
- 收到《违规信息整改通知》邮件如何处理?
- ECS云服务器FTP常见问题
- 无法安装阿里云开发者工具套件(SDK)
-
实例
-
操作运维 Linux
-
服务与应用
- 使用 Web 服务 为 ECS Linux 实例配置网站及绑定域名
- Linux 实例使用 Apache 的 .htaccess 文件限制 IP 访问
- 云服务器 ECS MySQL 设置数据库表名不区分大小写
- 云服务器 ECS Linux vsFTPd 报错 500 OOPS: vsftpd
- 云服务器 ECS Linux 系统 MySQL 备份的导入导出
- 云服务器 ECS Apache 开启伪静态模块
- MySQL 上传报错#1064 - You have an error in your SQL syntax
- ECS Linux 系统授权 MySQL 外网访问
- d 问题处理办法...
- 云服务器 ECS Linux 下 MySQL 无法访问问题排查基本步骤
- 云服务器 ECS Linux 服务器下 MySQL 自动备份脚本的使用方法
- 如何配置云服务器 ECS CentOS 6.5 系统 Apache HTTPS 服务
- 云服务器 ECS Linux 系统如何查看 MySQL 版本号
- 云服务器 ECS Apache环境下配置 404 错误页方法
- 云服务器 ECS Linux 服务器启用了TRACE Method 后的关闭方法
- 云服务器 ECS Linux 系统 Apache 301 重定向配置方法
- 云服务器 ECS Linux系统判断当前运行的 Apache 所使用的配置文件
- 云服务器 ECS Apache 如何关闭目录访问
- 云服务器 ECS 服务器隐藏 Apache 版本信息
- 云服务器 ECS Linux Web 环境添加站点
- 云服务器 ECS Linux判断 HTTP 端口监听状态
- ECS Linux 系统 Apache 服务日志
- 云服务器 ECS Linux Apache 客户端限速配置
- 云服务器 ECS Linux MongoDB 启动报错:child process failed
- 云服务器 ECS 网站访问出现 No input file specified 的解决方法
- 云服务器 ECS Apache、Nginx 配置支持跨域访问
- 云服务器 ECS Linux MySQL 无法远程连接问题常见错误及解决办法
- ysql-server-5.5...
- ECS Linux Apache 常见启动错误及解决办法
- 云服务器 ECS 服务器 MySQL Socket 连接与 TCP 两种连接方式说明
- ECS Linux MySQL 常见无法启动或启动异常的解决方案
- 云服务器 ECS Ubuntu 或 Debian 系统内如何卸载 MySQL 数据库服务
- 云服务器 ECS MySQL 编译安装支持 Innodb 引擎
- 云服务器 Linux MySQL 误删除授权表 root 记录
- 云服务器 ECS Linux 下 Apache 忽略网站 URL 的大小写的方法
- Linux 实例如何开启 MySQL 慢查询功能
- 云服务器 ECS Liunx系统服务器通过 prefork 模块限制 Apache 进程数量
- packet' bytes...
- 云服务器 ECS Linux 编译安装 Apache 添加 chkconfig 配置自启动
- 云服务器 ECS MySQL 修的默认字符集
- 修改nginx/Tomcat等Web服务的端口监听地址
- 20步打造最安全的Nginx Web服务器
- 云服务器 ECS Linux 系统 VSFTP 配置的 FTP 上传文件报错:553 Could not create file
- 云服务器 ECS Linux 服务器 nginx 禁止空主机头配置
- 云服务器 ECS Linux 配置 vsftpd 限制 FTP 账户访问其它目录
- er specified in 'ftp_username':ftp...
- 云服务器 ECS Linux Apache 运行参考的调整优化
- 云服务器 ECS Linux ftp 传输失败报错: 425 Security:Bad IP connection
- ECS Linux 基于 nginx 环境通过 .htaccess 配置 rewrite 伪静态示例
- Setuptools软件包版本太老导致ECS Linux安装AliyunCLI出错
- 云服务器 ECS Linux Ubuntu 系统下开启 sftp 功能
- from SFTP server...
- Nginx 配置文件中 root 与 alias 指令的区别
- Nginx 网站限速配置
- 云服务器 ECS Linux 连接 SFTP 报错:服务器拒绝了SFTP连接,但它监听FTP连接
- 云服务器 ECS 配置调取 SMTP 发信报错:authentication failure
- 云服务器 ECS Linux 任务计划 crontab 配置概要与常见问题
- 启动 Nginx 服务失败导致无法访问 Linux 实例上运行的网站
- AliyunCLI过滤用法概述
- 使用 Nginx 为 Linux 实例绑定多个域名
- Linux系统分析nginx或apache当天访问最多的IP
- 云服务器 ECS Linux 用 rpm 检查文件系统的完整性
- 阿里云CLI参数输入格式说明
- 云服务器 ECS Linux系统服务器无法输出系统日志显示 rsyslogd was HUPed 解决办法
- r session...
- 云服务器 ECS Linux php-fpm启动报错:allow_call_time_pass_reference
- 云服务器 ECS Linux Crontab 执行 PHP 程序失败
- 云服务器 ECS Linux 系统 php 程序配置显示错误信息
- 云服务器 ECS Linux 服务器隐藏 PHP 版本
- 云服务器 ECS PHP 程序无法识别短标签
- 云服务器 ECS WDCP 面板删除文件后空间没有释放
- 云服务器 ECS 搭建 WDCP 后台登陆后网页显示异常
- 云服务器 ECS Linux系统 Nginx Apache MySQL PHP 编译参数查看命令汇总
- 云服务器 ECS 网站访问报错:Discuz! Database Error
- 云服务器 ECS 内Java虚拟机崩溃出现大量 hs_err_pid*.log 日志
- 云服务器 ECS 服务器中微信公众平台 Token 验证失败常见原因
- r directory...
- 云服务器 ECS 上的网站访问时 header 出现多条:Vary:Accept-Encoding
- 云服务器 ECS 产品 PHP 环境开启 openssl
- 云服务器 ECS 主机宝 Linux 版 CentOS 64 位配置 HTTPS 站点
- 云服务器 ECS Linux 服务器安装主机宝后命令终端被卡住
- 云服务器 ECS Nodejs 通 过forever 设置后台运行及 Nodejs 链接 MySQL RDS
- 云服务器 ECS PHP 报错: 'read error on connection'
- 云服务器 ECS phpMyAdmin 报错:Wrong permissions on configuration file
- 云服务器 ECS Linux phpmyadmin 限制 IP 访问配置
- 云服务器 ECS Linux phpMyAdmin 配置导入大文件的 2 个方法
- 云服务器 ECS Linux 系统 WordPress 网站访问报错:建立数据库连接时出错
- 云服务器 ECS MySQL 忘记 root 密码解决办法
- Nginx 屏蔽 IP 方法概述
- nginx 无法启动的原因及解决方法
- Linux系统的ECS实例中执行yum更新命令返回“is not signed”错误
- Linux系统的ECS实例挂载NAS提示错误
- ECS实例Linux系统中执行crontab命令报错
- CentOS系统中执行yum命令报错
- 云服务器Linux系统扩容分区
-
系统配置
- 云服务器 ECS Linux 服务器发现未授权登录用户处理办法
- 云服务器 ECS Linux下通过 rm -f 删除大量文件时报错:Argument list too long
- 云服务器 ECS Linux 服务器下合理使用 su 和 sudo
- 云服务器 ECS Linux 系统下通过 innode 删除乱码的目录
- 云服务器 ECS Linux下使用 script 命令记录用户操作行为
- 云服务器 ECS Linux 误删除文件恢复方法介绍
- 云服务器 ECS Linux下的文件权限加固简介
- 云服务器 ECS Linux 文件系统只读问题分析指引
- 云服务器 ECS Linux下 shm 设备的安全设定
- 云服务器 ECS Linux 系统 tmp 目录的安全设置
- 云服务器 ECS Aliyun Linux 安装 gcc 报错:[Errno 14] HTTP Error 404
- 云服务器 ECS Linux Last 命令关于 reboot 记录的含义说明
- 云服务器 ECS Linux 配置只安装 64 位软件包
- 云服务器 ECS Linux 启动或禁止用户或 IP 通过 SSH 登录
- 云服务器 ECS SUSE10 环境下通过 YaST 安装软件
- 云服务器 ECS Linux 系统负载查询及分析说明
- Linux 实例中 YUM 的常用方法和常见问题处理
- 云服务器 ECS Ubuntu apt-get 在线安装软件和常见问题处理介绍
- 云服务器 ECS Linux IO 占用高问题排查方法
- 云服务器 ECS Linux 主机系统目录误操作权限修改为 777 的修复方法
- 云服务器 ECS 常用 Linux 系统软件源配置说明及常见问题说明
- 云服务器 ECS Linux 系统 CPU 占用率较高问题排查思路
- 云服务器 ECS Linux 常见安全检查方法
- 云服务器 ECS Linux 系统进程关联线程数统计及调整说明
- e end of /etc/fstab...
- 云服务器 ECS Linux 添加 root 权限账号
- 为 Linux 实例安装图形化桌面
- 云服务器 ECS Linux 修改 root 用户名称
- 云服务器 ECS Linux 主机删除文件后磁盘空间显示不变
- 云服务器 ECS Linux系统随机生成复杂密码方法
- 云服务器 ECS Linux 单用户模式下提示文件只读处理办法
- 云服务器 ECS Linux 保存用户登录操作命令记录
- 云服务器 ECS Linux 通过 testdisk 工具进行数据恢复操作概述
- 云服务器 ECS Linux 查看用户登录记录
- 云服务器 ECS Linux 服务器磁盘挂载报错:you must specify the filesystem type
- 云服务器 ECS Linux 服务器 umount 数据盘提示:device is busy
- 云服务器 ECS Linux 系统屏蔽某个 IP 的访问
- 云服务器 ECS Linux服务器删除文件权限不够
- 云服务器 ECS CentOS 系统限制普通用户切换到 root 管理员账号
- 云服务器 ECS Linux 服务器关闭磁盘自检
- 云服务器 ECS Linux 主机修改主机名
- ECS Linux云服务器tengine环境fail2ban屏蔽攻击ip
- 云服务器 ECS Linux 下 Tengine 结合 lua 防御 cc 攻击案例
- Ubuntu下使用slay命令结束某个用户的所有进程
- 云服务器 ECS Linux /tmp 目录文件定期清理原理
- with error 22...
- 云服务器 ECS Linux 系统 df 指令查看 used 加 avail 空间小于 size
- 云服务器 ECS Linux df 操作报错:no file systems processed
- 云服务器 ECS Liunx 系统服务器执行 ls 查询命令报错:command not found
- 云服务器 ECS Linux 执行命令会导致实际执行的是历史命令
- 云服务器 ECS Linux 系统检查系统上一次重启时间
- 云服务器 ECS Linux 系统添加“回收站”
- 云服务器 ECS Linux 系统盘数据转移方法
- 云服务器 ECS Linux 配置 history 命令显示操作时间、用户和登录 IP
- 云服务器 ECS Linux 修改编码格式
- 云服务器 ECS Linux 云服务器 quota 配额管理配置概述
- 云服务器 ECS Linux 使用 kpartx 命令读取分区表信息
- 云服务器 ECS CentOS 和 Red Hat Linux 系统设置服务自启动
- 云服务器 ECS Linux 服务器解压超过 4G 的 ZIP 压缩文件
- Linux实例安装VNC Server实现图形化访问
- 云服务器 ECS Linux 查看分区文件系统类型
- 云服务器 ECS Linux 服务器 xfs 文件系统不支持 acl 挂载选型
- 云服务器 ECS Linux 登入Shell 与非登入Shell 的区别
- promiscuous mode 说明...
- ECS Linux 密码修改报错 "Authentication token manipulation error" 的解决方法
- 云服务器 ECS Linux 通过 MD5 验证传输文件内容一致性
- ore than 120 seconds...
- 云服务器 ECS Linux 指令损坏导致执行时出现 Segmentation fault 段错误
- 云服务器 ECS Linux 系统中常见的日志文件介绍
- 云服务器 ECS Linux 报错:Failed to open private bus connection
- 云服务器 ECS CentOS 7 使用 ACL 设置文件权限
- 云服务器 ECS Linux 新购磁盘 fdisk 后在 /dev/ 中看不到相应设备文件
- 云服务器 ECS Linux Super block 损坏修复方法
- 云服务器 ECS Linux 查看物理 CPU、内存信息
- 云服务器 ECS linux 更改系统默认 Shell
- Window 系统上传文件到云服务器 ECS Linux 后显示乱码(出现 Dos 格式换行符)
- 云服务器 ECS Linux 实例安装中文环境
- 云服务器 ECS Linux CentOS 5.8 配置支持 ext4 文件系统
- 云服务器 ECS Linux df 命令长时间没有返回
- l/root...
- ECS Liunx系统进行时间同步出现ntp socket is in use exiting的解决方法
- 云服务器 ECS Linux 下使用 NTFS 文件系统示例
- 云服务器 ECS Linux 磁盘空间满(含inode满)问题排查方法
- 云服务器 ECS Linux 服务器通过 tail 查看日志提示空间不足
- 云服务器 ECS Linux 系统通过 df 查看磁盘空间为负数
- 云服务器 ECS Linux SWAP 配置概要说明
- 云服务器 ECS Linux Centos5.8 执行 mkfs.ext4 报错:command not found
- 云服务器 ECS Linux 服务器判断磁盘分区格式化
- 云服务器 ECS Linux CentOS7 修改 kdump 使用内存
- 云服务器 ECS Linux 更新操作最佳实践
- 云服务器 ECS Linux 磁盘空间常见问题处理方法
- 云服务器 ECS Linux 系统负载查询及分析
- 如何避免升级 Linux 实例内核后无法启动
- Linux系统中sysctl.conf文件设置参数不生效
- Linux系统的ECS实例中启动网卡失败
-
网络问题
- t known...
- 云服务器 ECS Linux CentOS 7 下使用iptables服务
- 云服务器 ECS Linux查看系统中网络流量的情况
- 云服务器 ECS Linux TC 流控软件导致服务器流量无法跑满
- 云服务器 ECS Ubuntu 系统防火墙策略的保存备份恢复方法
- 云服务器 ECS Linux 下 TCP/UDP 端口测试及验证方法说明
- 云服务器 ECS Aliyun Linux 服务器查看网关信息的方法
- ECS Linux 系统下安装 NetworkManager 服务导致网络出现异常
- 云服务器 ECS Linux 服务器内部无法解析域名
- ECS Linux 挂载了错误的文件系统导致网络服务异常
- 云服务器 ECS Linux 域名无法解析,dig 报错: isc_socket_bind: address in use
- while reading flags...
- 云服务器 ECS Linux Ubuntu 系统修改 resolv 文件中的 DNS信息后重启自动还原问题解决方法
- 云服务器 ECS Linux 系统下使用 dig 命令查询域名解析
- 云服务器 ECS Linux 带宽跑满时通过 iptraf 检查流量来源和防火墙封禁
- 云服务器 ECS Linux 新购服务器iptables无法启动
- 云服务器 ECS Linux 服务器带宽异常跑满分析解决
- 云服务器 ECS Linux 系统 ping 测试总时间异常
- 云服务器 ECS Linux 没有禁 ping 却 ping 不通问题排查分析
- Linux 实例常用内核网络参数介绍与常见问题处理
- 云服务器ECS Linux iptables 关联默认加载异常导致启动报错: modules are not loaded
- 云服务器 ECS iptables 规则全部禁止之后设置允许 php 访问
- 云服务器 ECS Linux 内核配置问题导致 NAT 环境访问异常
- 云服务器 ECS CentOS 7配置默认防火墙 Firewall
- 云服务器 ECS Gentoo 系统 下iptables 服务的配置概述
- 云服务器 ECS Linux系统使用 netstat 查看和检查系统端口占用情况
- 解决Linux系统 ping: sendmsg: Operation not permitted 问题
- 云服务器 ECS 服务器访问异常问题排查指引
- Nginx 502 bad gateway问题的解决方法
- ECS Linux服务器nginx禁止IP访问网站
- t table overflowt...
- Linux 常用内核网络参数与相关问题处理
- 网络性能测试方法
- Linux系统的ECS实例中NetworkManager服务导致网络异常
- 启动引导
-
远程登录 (SSH)
- ds available...
- 云服务器 ECS Linux SSH 无法远程登录问题排查指引
- SSH 登录时出现如下错误:Maximum amount of failed attempts was reached
- SSH 登录时出现如下错误:Host key verification failed
- SSH 登录时出现如下错误:requirement "uid >= 1000" not met by user "root"
- 登录 Linux 实例失败并报错:login: Module is unknown
- 云服务器 ECS Linux SSH 连接交互过程简介
- service sshd...
- SSH 服务启动时出现如下错误:main process exited, code=exited
- pipe...
- SSH 服务时出现如下错误:Bad configuration options
- SSH 服务启动时出现如下错误:fatal: Cannot bind any address
- SSH 服务启动时出现如下错误:error while loading shared libraries
- 云服务器 ECS Linux 结束正在登录的远程终端
- writable...
- 云服务器 ECS Linux SSH 启用 UseDNS 导致连接速度变慢
- SSH 连接时出现如下错误:error Could not get shadow infromation for root
- 云服务器 ECS CentOS 7 重启 sshd 服务
- SSH 连接时出现如下错误:pam_unix(sshdsession) session closed for user
- 云服务器 ECS Linux 通过 Putty 连接后中文显示乱码
- for 'nofile'...
- SSH 登录时出现如下错误:Too many authentication failures for root
- reset by peer...
- SSH 登录时出现如下错误:No supported key exchange algorithms
- SSH 登录时出现如下错误:Permission denied, please try again
- SSH 登录时出现如下错误:User root not allowed because not listed in
- 云服务器 ECS Linux系统 SSH 服务安全配置简要说明
- Linux 实例 SSH 连接安全组设置
- 云服务器 ECS Linux SSH 无法远程登录问题排查指引与 SSH 原理概述
- SSH 无法远程登录问题的处理思路
- 无法SSH登录CoreOS系统服务器
- 无法SSH登录Linux系统的ECS实例
- 使用DSA秘钥无法登录Linux系统的ECS实例
-
技术案例与工具
- 为什么 ECS Linux 实例执行 df 和 du 查看磁盘时结果不一致
- 云服务器 ECS Linux 软件源自动更新工具
- 在Linux实例上自动安装并运行VNC Server
- 云服务器 ECS Linux ECS 自动迁移工具
- 云服务器 ECS Linux 系统通过 Squid 配置实现代理上网
- 云服务器 ECS Linux Ubuntu 服务器 VPN 配置示例
- 如何使用 CentOS 6 实例配置 PPTP VPN 连接
- 云服务器 ECS Linux CentOS OpenVPN 配置概述
- 云服务器 ECS Linux SSH 客户端断开后保持进程继续运行配置方法
- 云服务器 ECS Linux 通过端口转发来访问内网服务
- Linux 自动格式化和分区数据盘
- 常见内核问题
-
服务与应用
-
操作运维 Windows
-
操作系统类问题
- 蓝屏
-
性能资源
- 【推荐】Windows虚拟内存不足问题的处理
- 配置 Windows 系统虚拟内存
- 云服务器 Windows 实例 CPU 高占用率的处理及工具推荐
- ECS Windows服务器开启自动更新造成内存或CPU过高
- Windows系统内存分析工具的介绍(进程管理器,资源管理器,性能监视器, VMMap, RamMap,PoolMon)
- ECS Windows资源监视器中查看到的两个内存图表不一致的原因
- ECS 腾讯通服务导致主机CPU占用高
- ECS Windows Server 2008 MetaFile设置占用内存限制
- ECS Windows内存能被识别但是不可用
- Windows进程和线程数的上限
- ECS Windows系统查看CPU内存信息
- ECS Windows 系统 SVCHOST.EXE进程占用资源(CPU,内存)较高的处理
- ECS Windows调整进程CPU占用示例
- ECS Windows 2008 Paged Pool Leak(页面缓冲池内存泄露)的排查实例
- 系统激活
- 时间服务
-
补丁更新
- 【推荐】Windows Update补丁更新失败的处理
- 【推荐】ECS Windows 2008 Windows Update 自动更新相关配置说明
- Windows Server操作系统使用Windows Update自动更新配置
- ECS Windows系统更新后设置重启
- ECS Windows更新补丁报错 0x80070643的处理(提示.net更新失败)
- ECS windows2008/2012 关闭自动更新
- ECS Windows更新补丁报错 0x80244019的处理
- ECS Windows Update 错误 80070008 或 8007000e
- ECS Windows2008 R2更新补丁报“8000FFFFwindows update 遇到未知错误”
- ECS Windows更新补丁报错 0x80243004的处理
- ECS Windows Server 2012系统更新或安装角色时出现"0x80073712(组件存储已损坏)"错误
- ECS Windows更新失败0x80070070的原因及解决方案
- ECS Windows查看补丁更新状态
- Windows系统执行系统更新出现80244022错误代码
- 的解决方法...
- 关于阿里云不再支持 Windows Server 2003 系统镜像
- Windows操作系统如何正确安装.NET Framework 3.5 SP1
-
文件系统
- 找不到磁盘管理(Windows Server 2008)
- 数据盘分区、格式化(Windows Server 2008)
- 清理 Windows Server 2012 WinSXS 目录
- 设定目录权限(Windows Server 2008 )
- 修改 Windows 实例分区盘符
- 服务器文件或者文件夹属性没有安全选项卡
- 无法访问 Windows 实例 C 盘
- Windows 实例临时文件占用过多磁盘空间
- 备份和还原 Windows 服务器注册表
- 无法删除 Windows 实例中的文件
- 显示及更改 Windows 实例桌面常用功能图标
- 禁用 Windows 服务器注册表编辑
- Windows 实例系统中无法看到数据盘
- ECS Windows 开机长时间乱码、黑屏等自检情况说明
- ECS Windows开启审核功能来记录文件删除操作
- Windows 系统内相关目录图标出现小黄锁
-
桌面配置
- ECS Windows Hypervisor Agent Watch服务的说明
- ECS Windows服务器桌面分辨率过高导致VNC花屏处理方法
- ECS Windows MMC无法初始化管理单元问题的处理
- ECS Windows 2008系统找不到控制面板
- Windows系统多核机器为什么在任务管理器里面只显示一核
- ECS Windows系统误结束explorer.exe进程导致无法显示桌面的修复方法
- Windows 系统cmd命令提示符打开提示“命令提示符已被系统管理员停用”解决方法
- ECS 关闭Windows系统的事件跟踪程序
- ECS Windows默认Path环境变量异常导致netstat等系统指令无法正常运行
- 使用 Windows 事件查看器查看实例运行日志
- ECS Windows系统环境变量异常无法运行命令
- Windows系统常用服务快捷启动
- 务检查"对话框...
- ECS Windows DISM配置库异常导致启动时出现"配置Windows功能失败"错误
- ECS Windows服务器打开事件查看器提示“事件日志服务不可用“的处理方法
- Windows 2008 服务器开始菜单中没有运行选项
- ECS Windows系统任务管理器数据滞后或暂停的原因
- 启动关机/登录登出
- 执行cscript命令激活Windows server 2008R2系统时发生异常
-
远程桌面
-
连接访问
- 【推荐】无法连接 Windows 实例远程桌面
- Windows服务器无法远程登录提示“试图登录 但是网络登陆服务没有启动”
- ECS Win2008 远程时提示"要登录到此远程计算机,您必须被授予允许通过终端登录的权限"的解决方法
- Mac 远程桌面无法验证我希望连接的 ECS Windows 2012的计算机身份
- ECS Windows远程桌面"连接被拒绝,因为没有授权此用户帐户进行远程登录"问题排查方法
- ECS Windows远程桌面中切换会话
- ECS Windows 【终端服务器】配置异常导致无法远程桌面访问
- 由于没有虚拟显卡支持导致ECS内运行或播放图形处理相关的软件或视频时出现卡顿现象
- 设置 Windows 实例远程连接防火墙
- Windows 实例远程连接失败提示协议错误
- Windows 2008远程连接提示“本地会话管理器 服务未能登录”的处理方法
- 启用【密码保护共享】导致ECS Windows远程访问出现"凭据无法工作"错误
- ECS Windows远程桌面连接报错:"远程桌面用户"组的成员拥有该权限
- ECS Windows 系统提示您的帐户已被停用
- 设置Windows 实例远程连接安全组
- 远程连接Windows实例时报错0x112f
- 登录Windows Server2008R2服务器提示未知的用户名或密码错误
- 错误,要求的函数不受支持)...
- Windows发起远程桌面时提示协议错误
-
服务配置
- 如何使用远程连接软件连接 Windows 实例
- ECS Windows 2012设置允许单个用户连接多个会话的方法
- Windows操作系统取消登录显示输入ctrl+alt+del的方法
- 组策略造成不能更改rdp 最大连接数
- ECS Windows Server 2003远程桌面无法修改壁纸
- Administrator被禁止登录任何终端服务器
- ECS Windows 服务器远程登录后无显示桌面
- ECS Windows远程桌面分辨率设置
- ECS 服务器远程登陆日志查询方法
- ECS Windows系统服务器的音频文件转到本地电脑播放
- Windows服务器远程无法复制粘贴的解决方法
- ECS Windows 系统服务器远程桌面连接通过 CapsLock 键关闭大小写的方法
- 查看和修改 Windows 实例远程桌面默认端口
- ECS Windows 系统如何临时关闭远程桌面
- ECS Windows 2008 系统重启 Remote Desktop Services 服务
- Windows 2008 &2012 远程协助无法勾选的处理方法
- ECS Windows 系统远程连接会话设置
- ECS Windows远程端口无法监听公网地址
- ECS Windows服务器打开终端服务配置管理程序时出现"无法完成操作"错误
- ECS Winodws 远程连接服务器映射本地电脑磁盘
- ECS Windows 2008允许远程协助选择灰显无法勾选
- Windows实例中修改远程连接数
- ECS Windows 设置开启和关闭一个用户多个远程桌面的方法
- License授权
-
连接访问
-
网络问题
-
网络连接问题
- 【推荐】 ECS Windows访问外部网络不通的处理
- 【推荐】 ECS Windows从外部访问网络不通的处理
- 【推荐】如何分析Windows实例带宽占用过高
- ECS Windows抓包工具(Wireshark, Network Monitor)的使用
- ECS Windows端口异常占用的处理
- ECS Windows 重置TCP/IP协议栈
- ECS Windows2008系统获取MAC地址
- 抓包信息使用Wireshark无法打开查看
- ECS Windows系统抓包工具Wireshark的安装使用
- 通过Chrome浏览器开发者工具排查网站打开慢
- ECS Windows Time_Wait过多导致访问外网失败
- ECS Windows服务器配置端口转发功能
- 利用Chrome的开发者工具分析网站访问缓慢的方法
- ECS Windows服务器ping外网提示一般故障处理方法
- 使用TCPPing或PSPing工具检测TCP延迟
- ECS Windows服务器添加静态路由方法
- Windows Server2012系统访问外部网站慢
- Windows系统主机不响应syn
- 网卡配置
- DNS问题
- Windows 防火墙
- VPN问题
-
网络连接问题
-
Web服务与数据库服务
-
IIS 服务
- Window 2003 IIS + MySQL + PHP + Zend 环境配置
- ECS Windows在不修改网站设置的情况下使用新数据盘
- ECS备份与恢复IIS7或者7.5所有站点及应用程序池的方法
- Windows系统服务器IIS7.5 Asp.net支持10万请求的设置方法
- Windows实例通过IIS搭建PHP环境
- Windows 实例搭建的 FTP 在外网无法连接和访问
- ECS Windows2012系统服务器删除IIS方法
- ECS Windows2003系统更改IIS日志路径避免系统盘用满的方法
- 云服务器 ECS Windows Server 安装 IIS 和 FTP
- ECS Windows系统服务器IIS 8安装WCF服务
- ECS Windows Server 修改IIS监听的IP地址
- ECS Windows系统服务器IIS注册64位和32位.NET方法
- Windows Server2008 IIS7创建站点教程
- ECS Windows Server IIS站点常见500错误及解决方案
- IIS7如何修改服务监听的IP地址
- IE浏览器访问网站调整显示详细错误信息的方法
- ECS Windows2008系统IIS7出现“无法加载站点/服务”问题的解决方法
- ECS Windows 2008 IIS7添加或修改已绑定的网站域名
- ECS Window2008系统IIS7环境程序访问提示HTTP错误401.3-Unauthorized
- ECS Windows 2008系统服务器在IIS中设置发送真实错误信息到浏览器
- ECS Windows2012系统安装IIS提示“服务器管理器WinRM插件可能已损坏或丢失”
- ECS Windows服务器IIS关联服务Windows Process Activation Services启动失败处理
- ECS Windows2008系统IIS7配置默认页面
- ECS Windows Server 通过 IIS 创建站点
- ECS Windows云服务器IIS和Tomcat共用80端口
- ECS Windows Server通过IIS启用Gzip压缩
- add”的重复集合项...
- ECS Windows系统服务器使用FTP连接遇到530 Login incorrect错误
- ECS Windows2003系统服务器通过attrib去除隐藏属性的方法
- ECS Windows2008设置IIS网站访问日志时间与本地时间记录相一致方法
- ECS Windows Server2012使用powershell安装IIS
- 此目录的内容”错误的处理...
- 当 Windows IIS 网站显示“500 - 内部服务器错误”,如何查看真实报错信息
- 访问 Windows 实例创建的 FTP 站点时报错:534 Policy requires SSL
- ECS Windows服务器网站出现“无法使用虚拟目录密码作为administrator在本地登录到网站目录”解决方法
- ECS Windows2008系统IIS7下设置特定文件不缓存
- ECS Windows系统使用自带监视器查看IIS并发连接数
- ECS 设置域名301重定向
- ECS Windows云服务器FTP上传失败排查
- ECS Windows 服务器安装了.NET 后还是找不到该版本的选项
- ECS Windows IIS 7.5 网站出现目录 [ ./Runtime/ ] 不可写
- ECS Windows环境IIS+PHP配置的网站访问遇到FastCGI 500错误
- ECS Windows Server通过IIS限制单个站点带宽
- acter exists...
- 访问ECS Windows IIS网站显示“500.19 - Internal Server Error”错误的处理
- ECS Windows下IIS网站无法访问出现"0x80070002系统找不到指定的文件"错误解决办法
- ECS Windows通过系统appcmd命令操作IIS7配置
- 访问ECS Windows IIS网站显示"503 Service Unavailable"错误的处理
- ECS Windows Server 导出/导出IIS配置方法
- ECS Windows权限问题导致IIS6环境下安装伪静态组件加载失败
- 如何在IIS7里设置实现访问.txt文件是下载模式
- ECS Windows Server 通过IIS限制、允许IP访问
- ECS Windows服务器修改通过IIS创建的站点的端口号
- 因添加ISAPI筛选造成IIS6环境下网站报错Service Unavailable
- 访问ECS Windows IIS网站显示403错误的处理
- ECS Windows Server IIS站点访问出现401.3报错
- ECS Windows Server 通过IIS配置伪静态
- ECS Windows服务器IIS网站设置禁止通过IP访问
- Windows 2012 IIS添加站点绑定域名的方法
- ECS Windows服务器IIS设置301重定向
- IIS8/IIS7运行ASP程序出现“ADODB.Connection错误'800a0e7a'未找到提供程序”
- ECS Windows2008系统IIS站点限制内存方法
- 服务(W3SVC)均处于运行状态”...
- 如何通过IIS7.5和php.ini配置文件调整网站后上传文件大小限制
- ECS Windows服务器站点报错ERR_CONTENT_DECODING_FAILED处理方法
- ECS Windows服务器IIS FTP登陆提示“530 valid hostname is expected”
- ECS Windows服务器IIS搭建HTTPS网站操作方法
- ECS Windows2008服务器设置404错误页面
- ECS Windows 2008 IIS设置访问日志属性
- ECS Windows 2008安装IIS6出现报错错误代码0x80070643
- 允许的父路径...
- ECS Windows云服务器ftp创建多个站点
- ECS Windows服务器基于IIS网站报错:无法识别的属性“targetFramework”
- ECS Windows Server 如何在IIS中添加MIME类型
- ECS Windows中IIS PHP访问时出现FastCGI Error 2147467259错误
- ECS设置404错误页面返回200状态码
- ECS Windows Server通过IIS设置和禁止FTP匿名登录
- 的ASP.NET设置...
- ECS Windows服务器添加IIS角色失败,报错:找不到源文件
- ECS Windows运行ASP网站连接Access数据库报错
- ECS Winodws系统服务器IIS日志详解
- ECS Windows IIS配置是报错:无法读取配置文件applicationHost.config
- ECS Windows服务器网站报错HTTP/1.1 新建会话失败
- ECS运行ASP网站访问提示“不是有效的Win32 应用程序”
- ECS Windows IIS访问报错Bad Request (Invalid Hostname)
- [ASP.NET]Session在多个站点之间共享解决方案
- ECS Windows服务器解决IIS7“ISAPI和CGI 限制”错误
- ECS Windows系统服务器IIS Admin Service 属性无法更改
- SQL Server 或 IIS 重启提示服务没有及时响应启动或控制请求
-
其它Web服务
- Windows Server 2008 一键安装Web环境全攻略
- ECS Windows服务器php环境开启openssl的方法
- Windows 下 Apache配置
- Windows 实例如何添加 FTP 用户
- FTP服务FileZilla Server上传提示550 Permission denied
- 如何解决WordPress更改新域名后使得网站正常运行
- 其他服务商网站迁入阿里云的方法
- Windows系统 PHP 开启PDO
- 站点百度爬虫联通率低
- ECS Windows filezilla server 连接出现421 Server is locked
- ECS安装WordPress环境后访问慢
- 海外Windows服务器访问google.com跳转到google.com.hk的解决方法
- Windows系统PHP程序报错:FastCGI 进程超过了配置的活动超时时限的解决方法
- ECS 解决windows系统下php.ini邮件配置正确不发送邮件的问题
- 01F9EDE6...
- CuteFTP新建站点连接及配置显示隐藏文件方法
- ECS Windows下Apache对客户端访问进行限速
- ECS Windows系统下开启php的fsockopen函数
- ECS Windows 2008系统安装管理配置phpStudy的说明
- Windows系统下Tomcat服务无法启动,返回错误“服务因 1 (0x1) 服务性错误而停止”
- ECS Windows系统下安装配置Tomcat方法
- 第三方环境WDCP安装教程
-
MS SQL Server
- ECS Windows安装SQL Server2005提示计算机名称异常
- ECS Windows系统事件查看器出现大量的审核失败记录,来源MSSQLSERVER
- ECS安装Sqlserver备份的导入导出
- ECS Windows Server 2008系统上安装配置MS SQL Server 2008数据库
- Windows安装SQL Server 2008教程
- ECS Windows服务器Access数据库不能写不能更新解决方法
- ECS Windows SQL Server 2008服务1433端口不监听问题的排查
- 网络问题导致ECS无法登录服务器的SQL Server
- 连接SQL Server 时出现网络相关的或特定实例的错误
- ECS Windows SQL Server 启动报错1069 "由于登陆失败而无法启动服务"的处理
- SQL Server客户端连接ECS自建的数据库提示无法访问的解决方法
- 自建SQL Server 2008 数据库修改列为自增列的方法
- ECS自建的SQL Server 2008忘记sa密码的处理方法
- 经典网络ECS配置SQL Server发布与订阅的方法
- SQL Server Manager创建作业失败c001f011的解决方法
- ECS Windows服务器SQL Server数据库分离/附加数据库
- ECS Windows 服务器限制SQL Server使用最大内存
- ECS Windows SQL Server 2008还原数据库导致处于"还原状态"的解决方法
- 的解决方法...
- ECS 备份还原SQL Server 数据库备份bak文件操作方法
-
其它数据库
- Windows Mysql启动出现1069错误“由于登录失败而无法启动服务”的处理方法
- mysql的binlog太大太多占用大量磁盘
- mysql乱码问题的解决方案
- ECS Windows下mysql服务启动后立即关闭
- ECS windows 2012 mysql 5.6数据库安装
- ECS Windows 服务器下如何彻底删除mysql
- ECS Windows系统安装Mysql 的方法
- ECS Navicat for MySQL远程连接报10038的错误
- windows系统服务器mysql报错InnoDB: Attempted to open解决方法
- mysql数据库设置远程连接权限
- ECS Windows服务器MySQL重置root密码
- ECS Windows环境中安装OpenSSL的步骤
- 访问ECS服务器的MySQL提示Can't get hostname for your address
- 常见数据库连接方式汇总
- 网页浏览器
-
IIS 服务
-
病毒安全
- 【推荐】ECS Windows三方杀毒防护软件的可能问题以及使用建议
- ECS Windows服务器安全狗的配置说明
- 云服务器 ECS 中病毒/木马了怎么办?
- ECS Windows下Openssl FREAK 中间人劫持漏洞的修复
- 防止黑客侵入你正在使用的Windows系统
- Windows BadTunel 安全漏洞及修复方案
- 服务器内部安装瑞星防护软件以后如何安装云盾aegis服务
- ECS Windows服务器安全加固
- 在ECS上架设SVN服后通过本地客户端提交代码被云盾拦截的原因
- ECS Windows被入侵或中毒后因被植入rnpasswd服务导致密码自动还原
- ECS Windows打开资源管理器报错overlayIcon1222.dll模块故障
- 云服务器 ECS Windows 安全审计日志简要说明
- AD域环境
-
服务应用
- 服务安装配置
-
Windows自带服务
- ECS Window系统共享无法连接
- Windows2008 添加计划任务的方法
- 客户端本地Windows7系统开启telnet命令
- ECS windows 2012启用“网络发现”失败的处理
- Windows Server2008 R2如何安装windows media player?
- ECS Windows 2008进程whichagent.exe报错
- Windows系统通过计划任务设置定时重启
- ECS Windows打开计划任务的时候提示“找不到远程计算机”的处理方法
- Remote Registry 服务被禁用导致ECS Windows安装DFS失败
- Windows系统服务器报错com surrogate已停止工作的解决办法
- ECS Windows Server 2012 SMB协议多通道导致内网传输不稳定处理方法
- ECS Windows系统启动服务报错1079的处理
- ECS Windows服务器之DFS文件同步
- ECS Windows服务器管理无法打开的解决方法
- Windows系统服务器配置文件共享以及网络磁盘映射的方法
- Windows系统提示找不到"Server Manager.lnk”的解决方法
- 控制台重置密码重启后无法访问服务器
- ECS Windows svchost.exe进程占用网络流量
- ECS Windows服务器通过系统计划任务实现开机自动运行脚本
- ECS Windows 系统设置登录时不自动启动“服务器管理器”
- Windows系统安装IIS证书无法指定域名
- 其它三方应用
-
操作系统类问题
-
故障处理
- App用户指南
-
视频专区
- 小筋斗 成功上云篇
- 小筋斗 平步青云篇
- 小助手系列之如何远程连接 Windows 实例
- 小助手系列之如何远程连接 Linux 实例
- 小助手系列之如何使用安全组
- 小助手系列之如何使用迁云工具
- ECS 经典网络与专有网络 VPC 特点介绍
- Windows ECS 实例挂载数据盘
- 挂载共享块存储到多个 ECS 实例
- 使用 SSH 密钥对连接 ECS 实例
- ECS SSH 密钥对介绍
- 导入镜像实践
- ECS 自定义镜像操作实践
- ECS 用户数据实践
- Windows实例搭建FTP站点
- Linux 实例环境安装 PHPWind
- Linux系统安装Phpwind
- 云吞铺子之如何配置安全组
- 云吞铺子之如何衡量Windows实例的磁盘性能
- 云吞铺子之Windows系统的排查思路
- 云吞铺子之三分钟教您做网站
- 相关协议
Linux实例带宽和CPU跑满或跑高排查
使用云服务器 ECS 时,若出现服务的速度变慢,或 ECS 实例突然断开,可以考虑服务器带宽和 CPU 是否有跑满或跑高的问题。若您预先创建报警任务,当带宽和 CPU 跑满或跑高时,系统将自动进行报警提醒。Linux 系统下,您可以按如下步骤进行排查:
- 定位问题。找到影响带宽和 CPU 跑满或跑高的具体进程。
分析处理。排查影响带宽和 CPU 跑满或跑高的进程是否正常,并分类进行处理。
- 对于 正常进程:您需要对程序进行优化或者升级服务器配置。
- 对于 异常进程:您可以手动对进程进行查杀,也可以使用第三方安全工具去查杀。
本文相关配置及说明已在 CentOS 6.5 64 位操作系统中进行过测试。其它类型及版本操作系统配置可能有所差异,具体情况请参阅相应操作系统官方文档。
如果云服务器 ECS Linux 系统的 CPU 持续跑高,则会对系统稳定性和业务运行造成影响。本文对 CPU 占用率较高问题的排查分析做简要说明。
CPU 跑满或跑高的问题定位
若云服务器 ECS 的 CPU 持续跑高,会对系统的稳定性和业务运行造成影响。Linux 系统下,查看进程的常用命令如下:
- ps -aux
- ps -ef
- top
Linux 系统中,通常使用 top 命令来查看系统的负载问题,并定位耗用较多 CPU 资源的进程。
操作步骤
通过控制台管理终端连接到 ECS 实例,参见使用远程连接功能连接 ECS 实例。
说明:资源负载异常时,通常无法通过 SSH 进行远程连接,建议您通过控制台管理终端进行连接。
通过 top 命令查看系统当前的运行情况。
- top - 17:27:13 up 27 days, 3:13, 1 user, load average: 0.02, 0.03, 0.05
- Tasks: 94 total, 1 running, 93 sleeping, 0 stopped, 0 zombie
- %Cpu(s): 0.3 us, 0.1 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st
- KiB Mem: 1016656 total, 946628 used, 70028 free, 169536 buffers
- KiB Swap: 0 total, 0 used, 0 free. 448644 cached Mem
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 1 root 20 0 41412 3824 2308 S 0.0 0.4 0:19.01 systemd
- 2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd
针对负载问题,您只需关注回显的第一行和第三行信息,详细说明如下。
top 命令的第一行显示的内容
17:27:13 up 27 days, 3:13, 1 user, load average: 0.02, 0.03, 0.05依次为 系统当前时间 、系统到目前为止已运行的时间、当前登录系统的用户数量、系统负载,这与直接执行 uptime 命令查询结果一致。top 命令的第三行会显示当前 CPU 资源的总体使用情况,下方会显示各个进程的资源占用情况。
通过字母键 P,可以对 CPU 使用率进行倒序排列,进而定位系统中占用 CPU 较高的进程。
说明:通过字母键 M, 您可以对系统内存使用情况进行排序。如果有多核 CPU,数字键 1 可以显示每核 CPU 的负载状况。
通过 ll /proc/PID/exe 可以查看每个进程 ID 对应的程序文件。
CPU 跑满或跑高的分析处理
CPU 的跑满或跑高,在确认具体的进程结果后,针对异常的进程,您需要通过 top 命令将其终止;而对于 kswapd0 进程导致的内存不足等问题,您需要对系统进行规格的升级或程序的优化。
使用 top 直接终止 CPU 消耗较大的进程
您可以直接在 top 运行界面快速终止相应的异常进程。操作步骤如下:
若您想要终止某个进程,只需按下小写的 k 键。
输入想要终止的进程 PID (top 输出结果的第一列)。例如,若您想要终止 PID 为 86 的进程,输入 86 后按回车即可。
操作成功后,界面会出现类似 Send pid 86 signal [15/sigterm] 的提示信息。按回车确认即可。
kswapd0 进程占用导致 CPU 较高
操作系统都用分页机制来管理物理内存,系统会把一部分硬盘空间虚拟成内存使用。由于内存的速度要比磁盘快得多,所以系统要按照某种换页机制将不需要的页面换到磁盘中,将需要的页面调到内存中。
kswapd0 是虚拟内存管理中负责换页的进程,当服务器内存不足的时候 kswapd0 会执行换页操作,这个换页操作是十分消耗主机 CPU 资源的。操作步骤如下:
通过 top 命令查看 kswapd0 进程。
检查该进程是否持续处于非睡眠状态,且运行时间较长。若是,可以初步判定系统在持续地进行换页操作,kswapd0 进程占用了系统大量 CPU 资源。
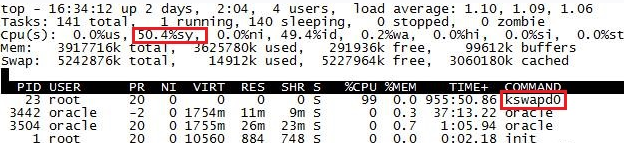
您可以通过 free 、ps 等指令进一步查询系统及系统内进程的内存占用情况,做进一步排查分析。
针对系统当前内存不足的问题,您可以重启 Apache,释放内存。
说明:从长远的角度来看,您需要对内存进行升级。
带宽跑满或跑高的分析处理
对于正常进程导致的带宽跑满或跑高的问题,需要对服务器的带宽进行升级。对于异常进程,有可能是由于恶意程序问题,或者是部分 IP 恶意访问导致,也可能是服务遭到了 CC 攻击。
通常情况下,您可以使用 iftop 工具或 nethogs 查看流量的占用情况,进而定位到具体的进程。
使用 iftop 工具排查
在服务器内部安装 iftop 流量监控工具。
- yum install iftop -y

服务器外网带宽被占满时,如果通过远程无法登陆,可通过阿里云终端管理进入到服务器内部,运行下面命令查看流量占用情况:
- iftop -i eth1 -P
注意:-P 参数将会显示请求端口。执行 iftop -i eth0 -P 命令,可以查看通过服务器哪个端口建立的连接,以及内网流量。举例如下:

在上图中,您可以查看到流量高耗的是服务器上 53139 端口和 115.205.150.235 地址建立的连接。
执行 netstat 命令反查 53139 端口对应的进程。
- netstat -tunlp |grep 53139

经反查,服务器上 vsftpd 服务产生大量流量,您可以通过停止服务或使用 iptables 服务来对指定地址进行处理,如屏蔽 IP 地址或限速,以保证服务器带宽能够正常使用。
使用 nethogs 进行排查
在服务器内部安装 nethogs 流量监控工具。
- yum install nethogs -y
通过 nethogs 工具来查看网卡上进程级的流量信息,若未安装可以通过 yum、apt-get 等方式安装。举例如下:
若 eth1 网卡跑满,执行命令
nethogs eth1。查看每个进程的网络带宽情况以及进程对应的 PID。
确定导致带宽跑满或跑高的具体进程。

若进程确定是恶意程序,可以通过执行
kill -TERM <PID>来终止程序。说明: 如果是 Web 服务程序,您可以使用 iftop 等工具来查询具体 IP 来源,然后分析 Web 访问日志是否为正常流量。日志分析可以使用 logwatch 或 awstats 等工具进行。
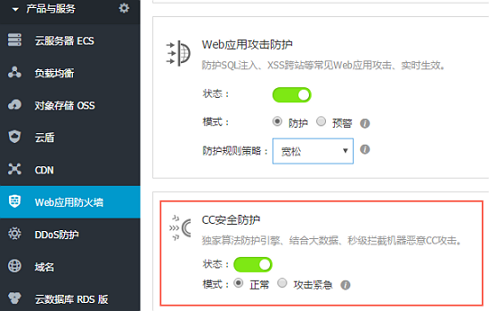
使用 Web 应用防火墙防御 CC 攻击
若您的服务遭受了 CC 攻击,请在 Web 应用防火墙控制台尽快开启 CC 安全防护。
登录 Web应用防火墙 控制台。
在 CC 安全防护中,启动状态按钮,并在模式中选择 正常。
相关参考文档,如下所示:
通过上述排查后,若服务器带宽或 CPU 仍然跑满跑高,请您记录前述的排查结果、相关日志信息或截图,然后联系售后进行处理。
FAQ
- 文档标签:
- Linux实例带宽和CPU跑满或跑高排查